



ArrayList分析
数组
数组是一种用连续的内存空间存储相同数据类型的线性数据结构
int[] array = {1,23,45,13,67,47};
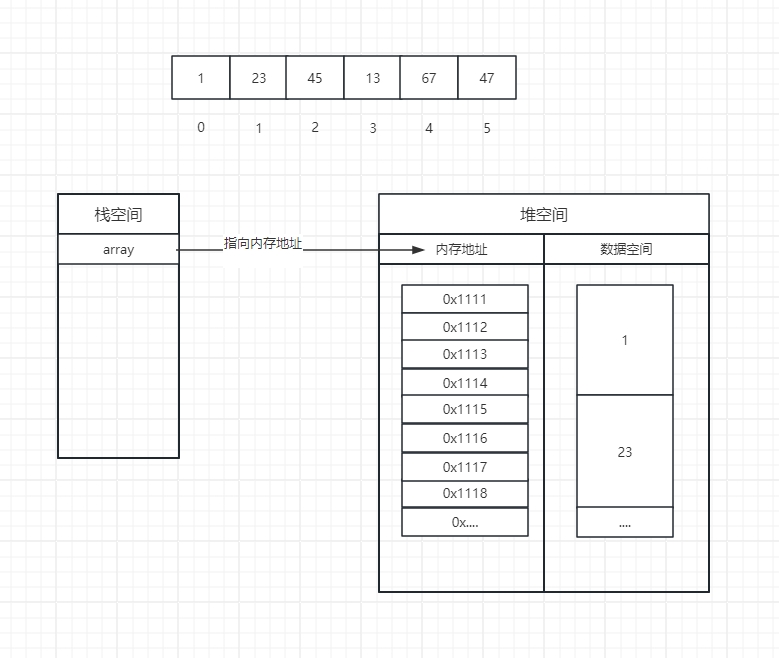
数组是如何获取其他元素的地址的
是通过寻址公式获取元素的地址
a[i] address = baseAddress + i * dataTypeSize
- baseAddress:数组的首地址
- i:元素下标
- dataTypeSize:数组中元素类型大小
为什么数组索引从0开始,从1开始可以吗?
- 在根据数组索引获取元素时,会用索引和寻址公式来计算内存所对应元素数据,寻址公式时:数组首地址+索引*存储数据的类型大小
- 如果数组的索引从1开始,寻址公式中就需要增加一次减法操作,对于CPU来说,就多了一次指令
操作数组的时间复杂度(查找)
- 随机查询(根据索引查询)
数组元素的访问是通过索引来访问的,计算机通过数组的首地址和寻址公式查找O(1) - 未知索引查询
查找数组内地元素 O(n)
查找排序后数组内的元素,可以使用二分查找 O(logn)
操作数组的时间复杂度(插入、删除)
数组是一段连续的空间,因此为了保证数组的连续性,会使得数组的插入和删除的效率变得很低
最好的情况是O(1),最坏的情况是O(n),平均情况下的时间复杂度是O(n)
ArrayList源码
成员变量
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
//用于默认大小空实例的共享空数组实例。
//我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存ArrayList数据的数组
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 所包含的元素个数
*/
private int size;
构造方法
/**
* 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
//其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: " +
initialCapacity);
}
}
/**
* 默认无参构造函数
* DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
//将指定集合转换为数组
elementData = c.toArray();
//如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
这里以无参构造函数创建的 ArrayList 为例分析。
add 方法
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
// 加元素之前,先调用ensureCapacityInternal方法
ensureCapacityInternal(size + 1); // Increments modCount!!
// 这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
注意:JDK11 移除了 ensureCapacityInternal() 和 ensureExplicitCapacity() 方法
ensureCapacityInternal 方法的源码如下:
// 根据给定的最小容量和当前数组元素来计算所需容量。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果当前数组元素为空数组(初始情况),返回默认容量和最小容量中的较大值作为所需容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 否则直接返回最小容量
return minCapacity;
}
// 确保内部容量达到指定的最小容量。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
ensureCapacityInternal 方法非常简单,内部直接调用了 ensureExplicitCapacity 方法:
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//判断当前数组容量是否足以存储minCapacity个元素
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容
grow(minCapacity);
}
我们来仔细分析一下:
- 当我们要
add进第 1 个元素到ArrayList时,elementData.length为 0 (因为还是一个空的 list),因为执行了ensureCapacityInternal()方法 ,所以minCapacity此时为 10。此时,minCapacity - elementData.length > 0成立,所以会进入grow(minCapacity)方法。 - 当
add第 2 个元素时,minCapacity为 2,此时elementData.length(容量)在添加第一个元素后扩容成10了。此时,minCapacity - elementData.length > 0不成立,所以不会进入 (执行)grow(minCapacity)方法。 - 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
grow 方法
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
// 将oldCapacity 右移一位,其效果相当于oldCapacity /2,
// 我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
// 如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如:10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
">>"(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
我们再来通过例子探究一下grow() 方法:
- 当
add第 1 个元素时,oldCapacity为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即newCapacity不比MAX_ARRAY_SIZE大,则不会进入hugeCapacity方法。数组容量为 10,add方法中 return true,size 增为 1。 - 当
add第 11 个元素进入grow方法时,newCapacity为 15,比minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入hugeCapacity方法。数组容量扩为 15,add 方法中 return true,size 增为 11。 - 以此类推······
这里补充一点比较重要,但是容易被忽视掉的知识点:
- Java 中的
length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性. - Java 中的
length()方法是针对字符串说的,如果想看这个字符串的长度则用到length()这个方法. - Java 中的
size()方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
hugeCapacity() 方法
从上面 grow() 方法源码我们知道:如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果 minCapacity 大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
// 对minCapacity和MAX_ARRAY_SIZE进行比较
// 若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
// 若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
// MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
ArrayList底层实现原理
- ArrayList底层是用动态数组实现的
- ArrayList初始化容量为0,当第一次添加数据的时候才会初始化容量为10
- ArrayList在进行扩容的时候是原来的1.5倍,每次扩容都需要拷贝数组
- ArrayList在添加数据的时候
- 确保数组已使用长度(size)+1之后足够存下下一个数据
- 计算数组的容量,如果当前数组已使用长度+1后大于当前的数组长度,则调用grow方法扩容,大约为原来的1.5倍
- 确保新增的数组有地方存储之后,则将新的元素添加到位于size的位置上
ArrayList list = new ArrayList(10)扩容了几次
该代码只是声明和实例化了一个ArrayList,指定了容量为10,所以未扩容
如何实现数组和List直接的转换
- 数组转List可以使用Arrays工具类的asList方法。该方法如果修改数组的内容,list也会受影响,因为底层使用的Arrays类中的一个内部类ArrayList来构造集合,因此数组和list指向的内存地址是一样的
- List转数组可以使用List的toArray方法,无参toArray方法返回Object数组,传入初始化长度的数组对象,则返回该数组对象。List.toArray转数组之后,如果修改了list内容,数组不受影响,当调用了toArray以后,在底层进行了数组拷贝,和原有的元素无关
链表
- 链表中的每一个元素被称之为结点(node)
- 物理存储单元上,是非连续、非顺序的存储结构
单向链表
每个结点包含两个部分,一个是存储数据的数据域,另一个是存储下一个结点地址的指针域,记录下一个结点地址的指针叫做后继指针next

双向链表
每个结点都有一个后继指针next和一个前驱指针prev

时间复杂度对比

ArrayList和LinkedList的区别
- 底层数据结构:ArrayList是动态数组的数据结构实现的,LinkedList是双向链表的数据结构
- 操作效率:ArrayList按下标查询,时间复杂度是O(1),因为内存是连续的,根据寻址公式,查找未知索引,时间复杂度为O(n),LinkedList也是需要遍历链表,所以也是O(n)
- 内存空间占用,ArrayList是连续的内存空间,需要的内存更少,LinkedList是双向链表,需要存储数据和两个指针,所以需要的内存更多
- 线程安全,ArrayList和LinkedList都是线程不安全的。如果需要保证线程安全:
- 在方法内部使用,局部变量则是线程安全的
- 使用线程安全的ArrayList和LinkedList:Collections.synchronizedList,内部使用了synchronize关键字,但是性能比较低
评论区